Mysql优化(一)
# sql语句性能查询Profile
Profile是sql性能监控工具,专门用来监控sql语句执行时间,用来达到sql性能监控的目的。
# Profile使用
Profile操作汇总
# 打开profile
SET PROFILING=1;
# 执行sql语句
SELECT * FROM endpoint_inventory ei;
# 分析sql执行时间
SHOW PROFILES;
# sql语句执行每个过程时间
SHOW PROFILE FOR QUERY 2;
# 分析每个过程做了什么
SHOW PROFILE ALL FOR QUERY 2;
# 关闭Profile
set PROFILING=0;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
如下图:
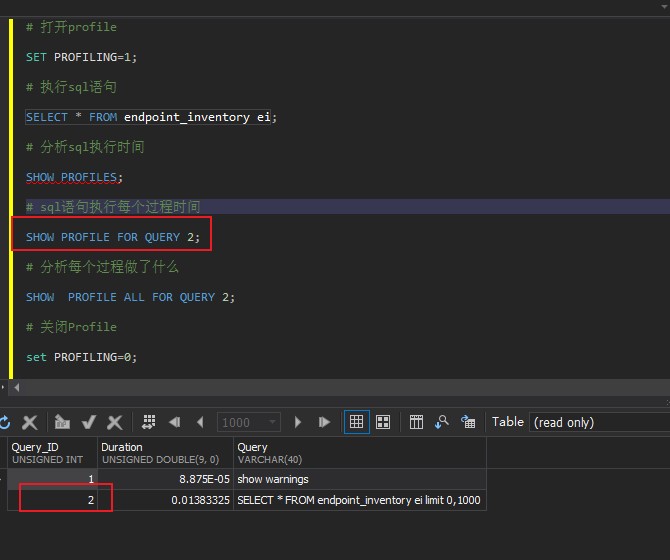
# Profile显示详细执行时间
SHOW PROFILE FOR QUERY 2;
# 2为sql语句监控编号
2
3
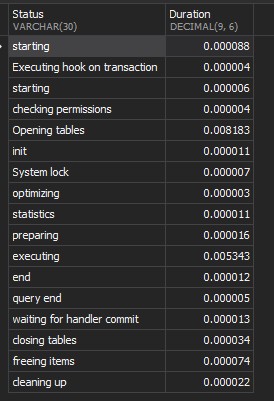
上图中纵向栏意义:
| 标识 | 意义 |
|---|---|
| starting | 开始 |
| checking permissions | 检查权限 |
| Opening tables | 打开表 |
| init | 初始化 |
| System lock | 系统锁 |
| optimizing | 优化 |
| statistics | 统计 |
| preparing | 准备 |
| executing | 执行 |
| Sending data | 发送数据 |
| Sorting result | 排序 |
| end | 结束 |
| query end | 查询 结束 |
| closing tables | 关闭表 /去除TMP 表 |
| freeing items | 释放物品 |
| cleaning up | 清理 |
# Profile显示详细执行过程
SHOW PROFILE ALL FOR QUERY 2;
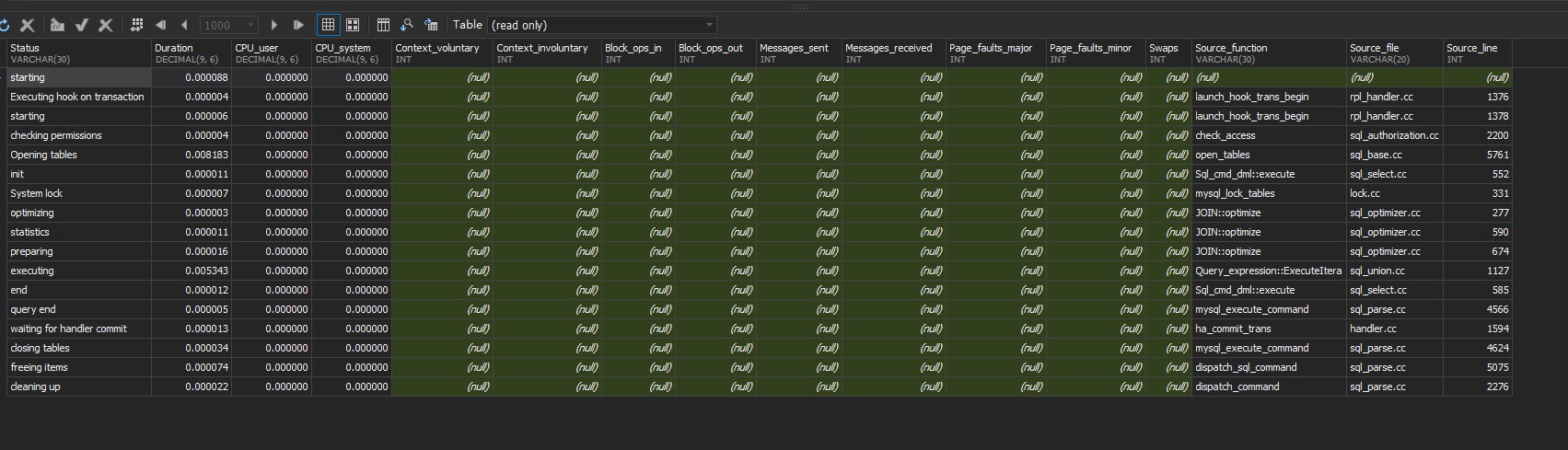
上图中横向栏意义:
| 标识 | 意义 |
|---|---|
| "Status": "query end" | 状态 |
| "Duration": "1.751142" | 持续时间 |
| "CPU_user": "0.008999" | cpu用户 |
| "CPU_system": "0.003999" | cpu系统 |
| "Context_voluntary": "98" | 上下文主动切换 |
| "Context_involuntary": "0" | 上下文被动切换 |
| "Block_ops_in": "8" | 阻塞的输入操作 |
| "Block_ops_out": "32" | 阻塞的输出操作 |
| "Messages_sent": "0" | 消息发出 |
| "Messages_received": "0" | 消息接受 |
| "Page_faults_major": "0" | 主分页错误 |
| "Page_faults_minor": "0" | 次分页错误 |
| "Swaps": "0" | 交换次数 |
| "Source_function": "mysql_execute_command" | 源功能 |
| "Source_file": "sql_parse.cc" | 源文件 |
| "Source_line": "4465" | 源代码行 |
# 慢查询
MySQL 慢查询的相关参数解释:
slow_query_log :是否开启慢查询日志,1表示开启,0表示关闭。
log-slow-queries :旧版(5.6以下版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
slow-query-log-file:新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
long_query_time :慢查询阈值,当查询时间多于设定的阈值时,记录日志。
log_queries_not_using_indexes:未使用索引的查询也被记录到慢查询日志中(可选项)。
log_output:日志存储方式。log_output='FILE'表示将日志存入文件,默认值是'FILE'。log_output='TABLE'表示将日志存入数据库,这样日志信息就会被写入到mysql.slow_log表中。MySQL数据库支持同时两种日志存储方式,配置的时候以逗号隔开即可,如:log_output='FILE,TABLE'。日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源,因此对于需要启用慢查询日志,又需要能够获得更高的系统性能,那么建议优先记录到文件。
1、查询系统是否开启了慢查询
SHOW VARIABLES LIKE '%slow_query_log%';
2、设置慢查询
SET GLOBAL slow_query_log=1; # 1:开启 0:关闭
慢查询配置文件路径(mysql安装路径下):C:\ProgramData\MySQL\MySQL Server 8.0\my.ini
慢查询记录时间
show variables like 'long_query_time%';
设置慢查询时间
set global long_query_time=4;
日志分析工具:mysqldumpslow
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具mysqldumpslow
# 查询计划Explain
查询计划是分析sql语句执行计划,了解sql语句如何从表中查询到目标数据。
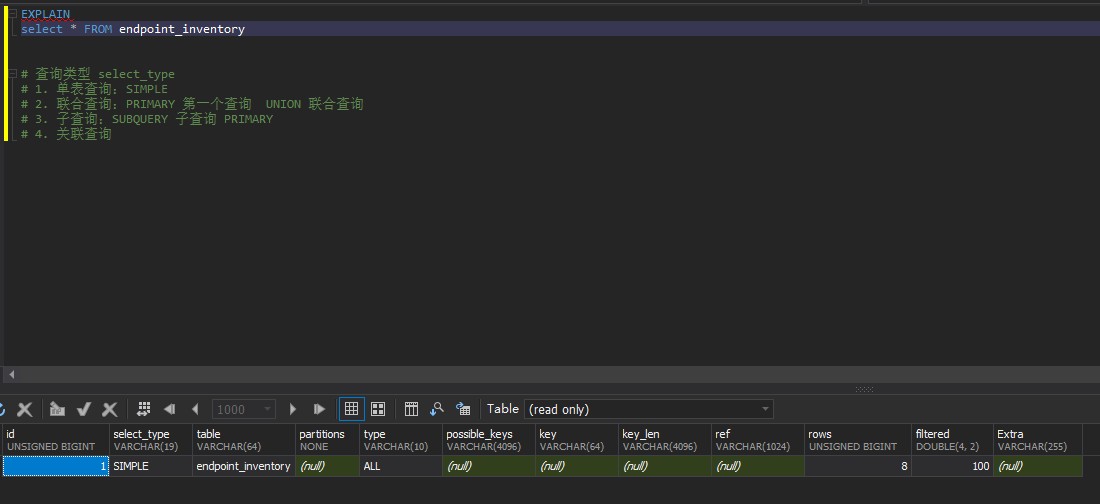
| 标识 | 意义 |
|---|---|
| id: | 查询的唯一标识 |
| select_type: | 查询的类型 |
| table: | 查询的表, 可能是数据库中的表/视图,也可能是 FROM 中的子查询 |
| type: | 搜索数据的方法 |
| possible_keys: | 可能使用的索引 |
| key: | 最终决定要使用的key |
| key_len: | 查询索引使用的字节数。通常越少越好 |
| ref: | 查询的列或常量 |
| rows: | 需要扫描的行数,估计值。通常越少越好 |
| extra: | 额外的信息 |
# 执行计划 - Id
select 查询的序列号,包含一组数字,表示查询中执行select字句或操作表的顺序。
有以下情况:
Id相同,执行顺序由上到下;
Id不同,如果是子查询,Id的序号会递增,Id越大优先级越高,越先被执行。
# 执行计划 - select_type
SIMPLE: 简单查询,不包含子查询和union
PRIMRARY: 包含子查询时的最外层查询; 使用union时的第一个查询
UNION: 包含union的查询中非第一个查询
UNION RESULT 临时结果
DEPENDENT UNION: 与 UNION 相同,但依赖外层查询的结果
SUBQUERY: 子查询
DEPENDENT SUBQUERY: 依赖外层查询的子查询
DERIVED: 用于 FROM 中的子查询(中间表)
# 执行计划 - type
type 字段描述了查询的方式,从好到坏为:
null: 不需要访问索引和表即可完成, 示例:
SELECT 1;const: 表中仅有一行匹配,在分解查询计划时直接将其读出作为常量使用。system 是 const 类型的特例; 示例:
select * FROM qrtz_user WHERE Id=1;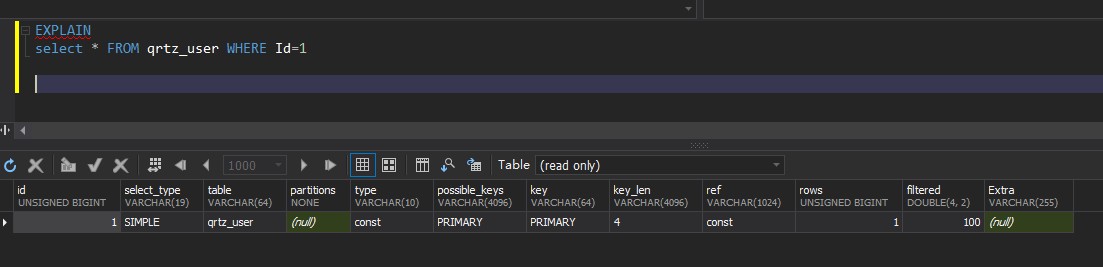
eq_ref:使用 PRIMARY KEY 或 UNIQUE KEY 进行关联查询;
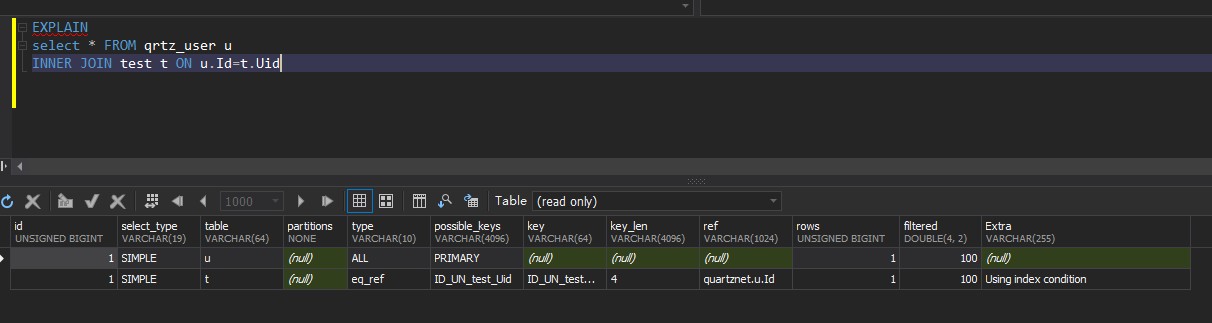
ref: 使用允许重复的索引进行查询;
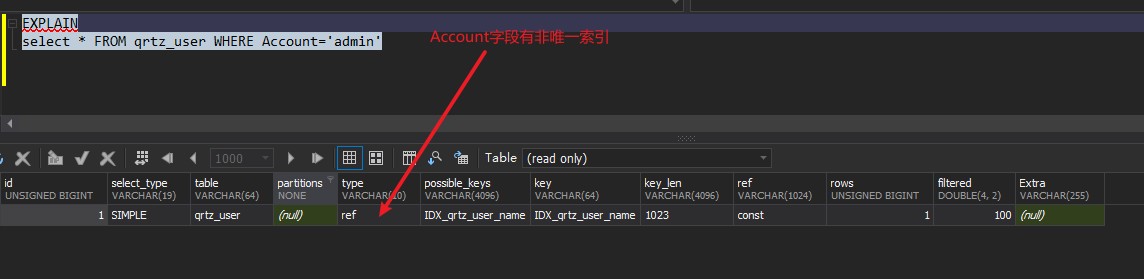
range: 使用索引进行范围查询;
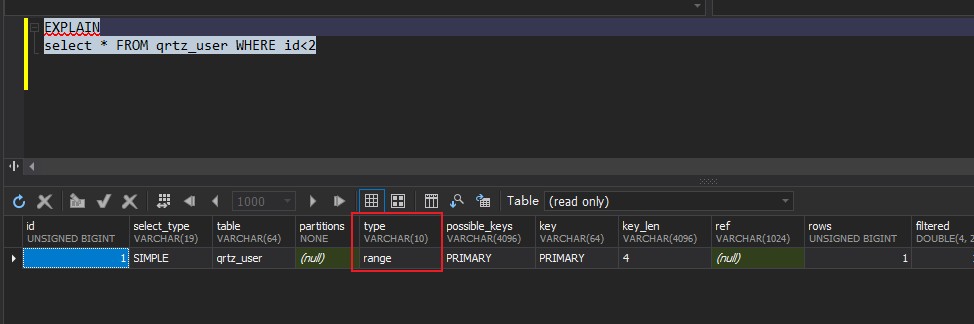
index: 在索引上进行顺序扫描。常见于在多列索引(组合索引)中未使用最左列进行查询;
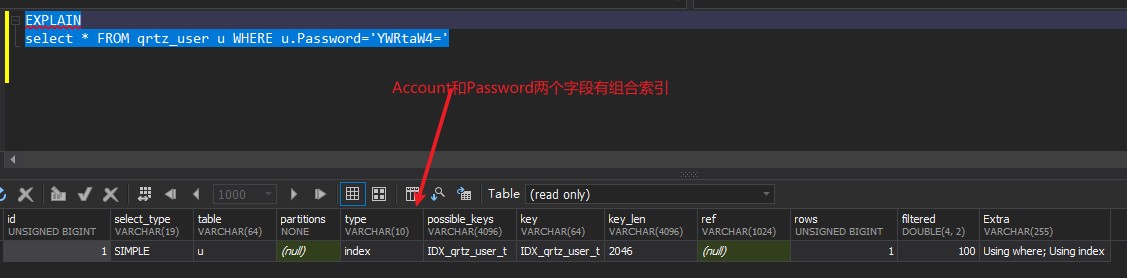
all: 扫描全表,最坏的情况。
# 执行计划 - possible_keys
可能使用的索引。
# 执行计划 - keys
实际使用的索引,如果为NULL,则没有使用索引,查询中若使用了覆盖索引,则该索引和查询的select字段重叠
# 执行计划 - key_len
索引使用的字节数,相当于长度
char和varchar跟字符编码也有密切的联系,latin1占用1个字节,gbk占用2个字节,utf8占用3个字节。(不同字符编码占用的存储空间不同)


# 执行计划 - ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值
# 执行计划 - rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
# 执行计划 - Extra
extra 列显示了查询过程中需要执行的其它操作,有些情况应尽力避免。
using filesort: 查询时执行了排序操作而无法使用索引排序。虽然名称为'file'但操作可能是在内存中执行的,取决是否有足够的内存进行排序。 应尽量避免这种filesort出现。
using temporary: 使用临时表存储中间结果,常见于ORDER BY和GROUP BY语句中。临时表可能在内存中也可能在硬盘中,应尽量避免这种操作出现。
using index: 索引中包含查询的所有列不需要查询数据表(回表)。可以加快查询速度。
using where: 使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给客户端。
using index condition: 索引条件推送(MySQL 5.6 新特性),服务器层将不能直接使用索引的查询条件推送给存储引擎,从而避免在服务器层进行过滤。
distinct: 优化distinct操作,查询到匹配的数据后停止继续搜索